¡Vamos a hablar de los Large Language Models (LLM)! Estos están causando revuelo y no hay empresa que no quiera involucrarse en esto ya mismo. En este post, voy a mostrar como se puede potenciar un proyecto con LLM, y de paso, vamos a explorar temas interesantes como los motores de búsqueda, personalización, embeddings, vector similarity entre otros temas…
Los motores de búsqueda
Los motores de búsqueda potencian la experiencia del usuario. Imagina una tienda en línea: con un motor de búsqueda eficiente, los clientes pueden localizar rápidamente los productos que desean, lo cual se traduce en un aumento de las ventas y mayor satisfacción del cliente.
Aunque es tentador ver a un motor de búsqueda únicamente como un dispositivo que arroja resultados a partir de una entrada, esa visión se queda corta cuando se trata de proporcionar una experiencia al usuario totalmente centrada en él. Es aquí donde otros componentes entran en juego para complementar la función de los motores de búsqueda:
Personalización:
En el contexto de un motor de búsqueda, la personalización puede involucrar la adaptación de los resultados de búsqueda basados en el historial de búsquedas y comportamiento del usuario. Por ejemplo, si un usuario ha estado buscando frecuentemente artículos de jardinería en una tienda en línea, el motor de búsqueda puede personalizar los resultados de las futuras búsquedas para destacar productos de jardinería, incluso cuando la consulta de búsqueda sea genérica, como “artículos para el hogar”.
Discovery:
En relación con los motores de búsqueda, el proceso de discovery puede ser mejorado mediante la implementación de características como la “búsqueda semántica” y las “recomendaciones basadas en la búsqueda”. Por ejemplo, si un usuario busca “novelas de ciencia ficción”, el motor de búsqueda podría incluir en los resultados una sección de “podrías estar interesado en…” que muestra novelas gráficas de ciencia ficción, ampliando así el descubrimiento de nuevos productos que el usuario podría no haber considerado inicialmente.
Comenzamos
Imagina que tienes una plataforma de venta de perfumes la cual quieres potenciar con un buscador y LLM para mejorar su interacción con los usuarios. Adentrémonos en cómo podríamos llevar a cabo esta implementación.
Pongámonos en contexto 🤓
Tenemos una tienda en línea dedicada a la venta de perfumes, con una gran diversidad de fragancias a disposición de cualquier persona. Dado que contamos con miles de opciones, comprendemos que encontrar el perfume perfecto puede ser desafiante. Por eso, estamos considerando la implementación de un buscador, para que nuestros clientes puedan localizar rápidamente sus productos deseados.
Creación del Buscador 🪵
Ahora que hemos hablado un poco de los buscadores y el caso de uso que tomamos para desarrollar, es hora de poner manos a la obra y aprender a implementar uno en nuestra tienda de perfumes en línea. ¿Alguna vez te has preguntado cómo se crea un buscador desde cero? En este segmento, vamos a abordar precisamente eso.
Revisaremos el proceso de construcción de un buscador de productos para nuestra tienda de perfumes utilizando tecnologías como ChromaDB, SBERT, ChatGPT, prestando especial atención en los procesos más comunes a la hora de desarrollar un buscador.
Los datos (documentos):
Abordemos el tema de los datos. Los datos son la totalidad de información que nuestra empresa tiene a su disposición para analizar y desarrollar productos. Una pequeña fracción de estos datos representa las entidades que estamos interesados en explorar.
Consideremos los documentos como archivos JSON, los cuales contienen información relevante de nuestros productos, tales como el nombre del producto, su marca, descripción y otros metadatos. En este caso, disponemos de los siguientes:
[
{
"id": 2190,
"name": "1270 Eau de Parfum",
"brand": "Frapin",
"description": "Named for the year the Frapin family established itself in the Cognac region of France, 1270 was created by Beatrice Cointreau, great granddaughter of Pierre Frapin.",
"notes": "exotic woods, spice, raisin, vine flowers, pepper, candied orange, nut, hazelnut, prune, cocoa, coffee, leather, woods, white honey, vanilla",
"image_url": "https://static.luckyscent.com/images/products/22600.jpg?width=400&404=product.png"
},
{
"id": 2190,
"name": "Ombre Leather Eau de Parfum",
"brand": "Tom Ford",
"description": "True luxury doesn't shout. If you've been on the hunt for the perfect leather but been either smothered by an avalanche of powdery florals or slapped around the face by a Cossack's oily winter boot, then breathe a sigh of relief because “your” leather has finally arrived.",
"notes": "Violet leaf, cardamom, jasmine sambac, black leather, white moss",
"image_url": "https://static.luckyscent.com/images/products/807000.jpg?width=400&404=product.png"
}
...
]
El JSON que poseemos es crucial para entender las características individuales de cada perfume.
Estos documentos serán de gran utilidad porque son las propiedades que más usaría el usuario para buscar dentro de nuestro catálogo de productos, entonces estos serán los elementos que queremos convertir a embedings.
La cuestión es: ¿Cómo generamos un embedding que contemple estas tres propiedades? Algunas opciones serían:
- Generar un embedding individual para cada propiedad (nombre, descripción, notas) y luego sumarlos o calcular su promedio.
- Concatenar las tres propiedades y generar un embedding del texto resultante.
Optaremos por la segunda opción para facilitar el procesamiento. Formaremos un nuevo atributo llamado ‘text_to_embedding’ utilizando las propiedades de nombre, descripción y notas de cada producto de la siguiente manera:
[
{
"id": 2190,
"name": "1270 Eau de Parfum",
"brand": "Frapin",
"text_to_embedding": "Named for the year the Frapin family established itself in the Cognac region of France, 1270 was created by Beatrice Cointreau, great granddaughter of Pierre Frapin. Exotic woods, spice, raisin, vine flowers, pepper, candied orange, nut, hazelnut, prune, cocoa, coffee, leather, woods, white honey, vanilla",
"image_url": "https://static.luckyscent.com/images/products/22600.jpg?width=400&404=product.png"
},
{
"id": 2191,
"name": "Ombre Leather Eau de Parfum",
"brand": "Tom Ford",
"text_to_embedding": "Ombre Leather Eau de Parfum. True luxury doesn't shout. If you've been on the hunt for the perfect leather but been either smothered by an avalanche of powdery florals or slapped around the face by a Cossack's oily winter boot, then breathe a sigh of relief because 'your' leather has finally arrived. Violet leaf, cardamom, jasmine sambac, black leather, white moss",
"image_url": "https://static.luckyscent.com/images/products/807000.jpg?width=400&404=product.png"
}
...
]
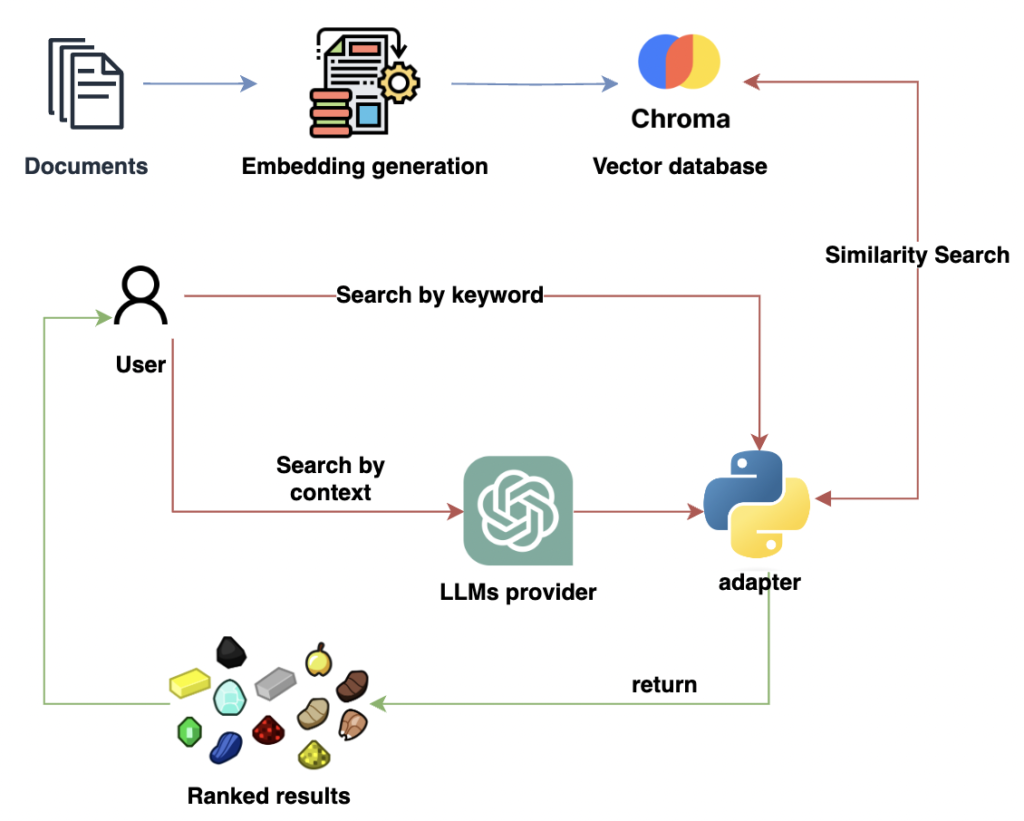
Hasta ahora, hemos preparado nuestros datos para ser convertidos en embeddings. En este punto, entra en juego ChromaDB, una base de datos de vectores de código abierto que nos facilita enormemente el almacenamiento de vectores. Algunas características más destacadas de ChromaDB:
- Almacena los documentos en un índice de tipo HNSW, es una forma bastante eficiente de realizar búsquedas entre vectores, de tal forma que podemos tener una gran cantidad de documentos dentro de la base de datos, garantizando que la búsqueda será lo más rápido posible, este tipo de índice es también usado por tecnologías como Elasticsearch.
- Puede convertir automáticamente el texto que se inserta en la estructura de datos en su representación vectorial. Utiliza un modelo predeterminado, lo que nos ahorra tener que calcular los embeddings en un proceso separado.
Por default, usa el modelo all-MiniLM-L6-v2 que es una versión preentrenada de SBERT especial para obtener embeddings de oraciones completas, en vez de palabra por palabra, como ocurría con BERT
En realidad, es tan sencillo como insertar un texto, y ChromaDB se encargará de usar un modelo para convertirlo en un formato vectorial, que quedará almacenado en la base de datos.
Instalemos la librería:
pip install chromadbProcedemos a iniciar el cliente de ChromaDB, el cual utilizaremos para interactuar con la base de datos:
import chromadb
chroma_client = chromadb.Client()Ahora crearemos una colección de datos para almacenar nuestros datos de fragancias:
collection = chroma_client.create_collection(name="fragances_collection")Dentro de esta colección insertaremos cada uno de los documentos de la siguiente forma:
for i, row in enumerate(array_with_docs):
try:
collection.add(
documents=[row['text_to_embedding']],
metadatas=[{"image_url": row['image_url'], "name":row['name'], "brand":row['brand']}],
ids=[str(row['id'])]
)
except Exception as e:
print(f"An error occurred: {e}, {row}")
De esta forma, insertamos todos los documentos en la base de datos y, automáticamente, tomará el texto que estamos insertando y lo almacenará como vector.
Embeddings Ingestados
Ya que insertamos dentro de nuestra base de datos todos nuestros documentos, podemos hacer querys de texto de la siguiente forma:
results = collection.query(
query_texts = ["ombre leather"],
n_results = 3,
include = ["metadatas", "distances"]
)output:
{
"ids": [["879", "1412", "1331"]],
"embeddings": None,
"documents": None,
"metadatas": [
[
{
"image_url": "https://static.luckyscent.com/images/products/807000.jpg?width=400&404=product.png",
"Name": "Ombre Leather Eau de Parfum",
"Brand": "TOM FORD Signature",
"Notes": "Violet leaf, cardamom, jasmine sambac, black leather, white moss"
},
{
"image_url": "https://static.luckyscent.com/images/products/69118.jpg?width=400&404=product.png",
"Name": "African Leather Eau de Parfum",
"Brand": "MEMO",
"Notes": "Bergamot, cardamom, saffron, cumin, geranium, patchouli, oud, leather, vetiver, musk"
},
{
"image_url": "https://static.luckyscent.com/images/products/73406.jpg?width=400&404=product.png",
"Name": "Regent Leather Eau de Parfum",
"Brand": "Thameen",
"Notes": "Vanilla, lemon, saffron, labdanum, gurjum, cedar, patchouli"
}
]
],
"distances": [[0.4199996590614319, 0.9000111222267151, 0.966914713382721]]
}
Como vemos en la respuesta de arriba, realizamos una búsqueda de la palabra, ‘ombre leather’ la cual corresponde al nombre de un perfume, entonces internamente cada que realizamos una busqueda Cromadb hace lo siguiente:
- Tokenizar el input.
- Obtener el vector embedding.
- Buscar los vectores más cercanos en el index.
- Retornar el top vectores más cercanos.
Ahora vamos a probar varias formar de realizar búsqueda con esta información que insertamos, podemos realizar búsquedas de estilo:
- Nombre del perfume
- Descripción
- Notas
Veamos como se va cada tipo de búsqueda, le he agregado una interfaz gráfica hecha con Gradio para tener una mejor vista de los resultados.
- Búsqueda por nombre
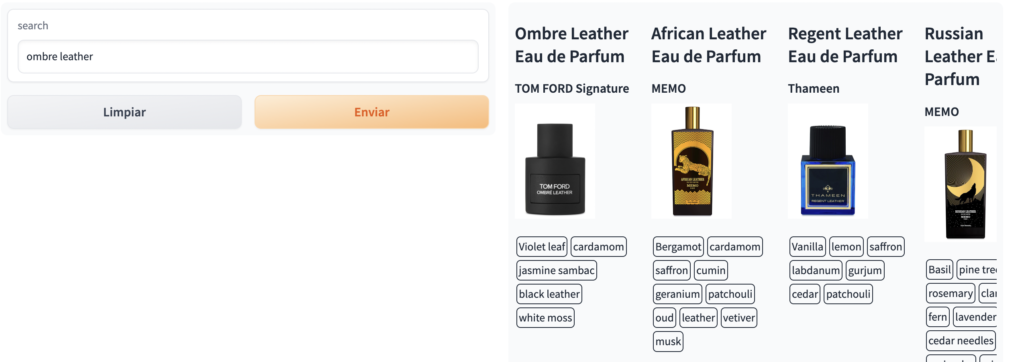
- Búsqueda por Notas
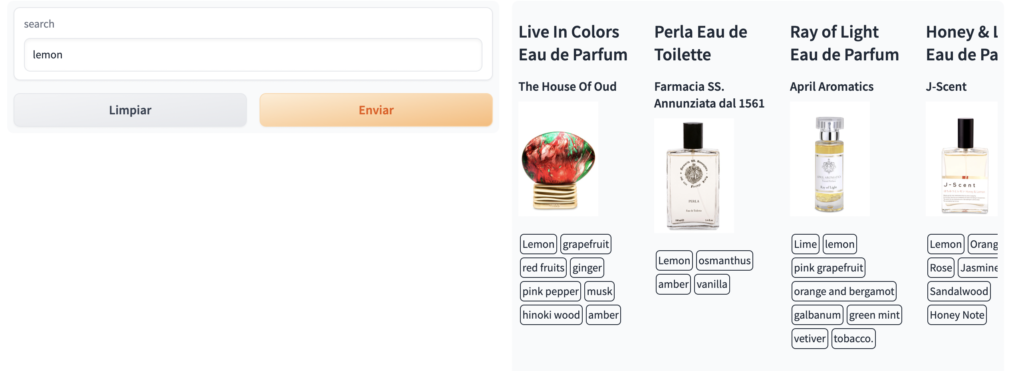
Con esto podemos ver como está funcionando el buscador de manera correcta para esos dos tipos de búsqueda, no hemos hecho pruebas exhaustivas, pero supongamos que todo está funcionando bien y ahora queremos potenciar nuestro buscador con LLM.
LLM al rescate
Los perfumes representan un caso idóneo, ya que no son simplemente un producto de consumo cotidiano. En general, los usuarios buscan perfumes para ocasiones especiales y, debido a la amplia variedad disponible, frecuentemente necesitan ayuda para decidir cuál escoger.
Imagina a alguien que no está familiarizado con la complejidad de los perfumes, con su diversidad de notas y aromas, pero que desea comprar una fragancia para un evento especial. Es en este punto donde los LLM desempeñan un papel crucial. Podemos hacer que actúen que como expertos en perfumes, capaces de comprender el contexto proporcionado por el cliente y sugerir las fragancias o notas más adecuadas para cada situación.
Con el prompt siguiente definimos a nuestro LLM experto en perfumes más las condiciones que debe cumplir.
text = """Can you suggest a fragrance for the summer?"""
prompt = f"""
Recommends the most suitable perfume notes for a given situation.
<AVAILABLE_NOTES>:
[vetiver, neroli, orange blossom, white musk, honey, leather, violet, patchouli, geranium, ginger, magnolia, orris, grapefruit, jasmine, cumin, vanilla, rose, gaiac, cedar, sandalwood, styrax, tobacco, pepper, cardamom, nutmeg, ambergris, pink pepper, castoreum, incense, bergamot, ylang-ylang, black pepper, musk, lily of the valley, iris, moss, lavender, coriander, labdanum, galbanum, saffron, benzoin, tonka bean, lemon, mandarin, myrrh, clove, ylang ylang, heliotrope, tuberose, frankincense, cedarwood, oakmoss, amber, cinnamon, tonka, oud, osmanthus].
RULES:
1. Use the <AVAILABLE_NOTES>
2. If the note is not on the list, propose different, maximum two.
4. Maximum 5 recommendations
Situation: ´´´
I want a perfume that reminds me of a forest
´´´
Answer: cedarwood, oakmoss, moss, vetiver, pine
Situation: ´´´
Hello people, my brother asked me for a recommendation of a perfume that smells fresh and of a clean man, which one would you recommend?
´´´
Answer:
"""En nuestra selección de perfumes, contamos con una vasta variedad de 3257 notas distintas. Sin embargo, debido al límite de contexto de ChatGPT, solo presentaremos las 50 notas más destacadas vistas en <AVAILABLE_NOTES>. A pesar de esto, el LLM tendrá la flexibilidad de sugerir hasta dos notas adicionales que no estén en nuestra lista.
Esta estrategia permite al LLM seleccionar de nuestras notas disponibles, las que mejor se ajusten a la situación específica del cliente.
Entonces supongamos que alguien quiere adquirir un perfume para alguna ocasión especial, por ejemplo probemos esta pregunta que me encontré en un foro de perfumes:
Hello people, my brother asked me for a recommendation of a perfume that smells fresh and of a clean man, which one would you recommend?El LLM nos responde:
bergamot, lavender, cedar, sandalwood, musk
Entonces recordamos que tenemos la búsqueda por notas, podemos usar este output del LLM como el input para nuestra base de datos semántica de la siguiente forma:
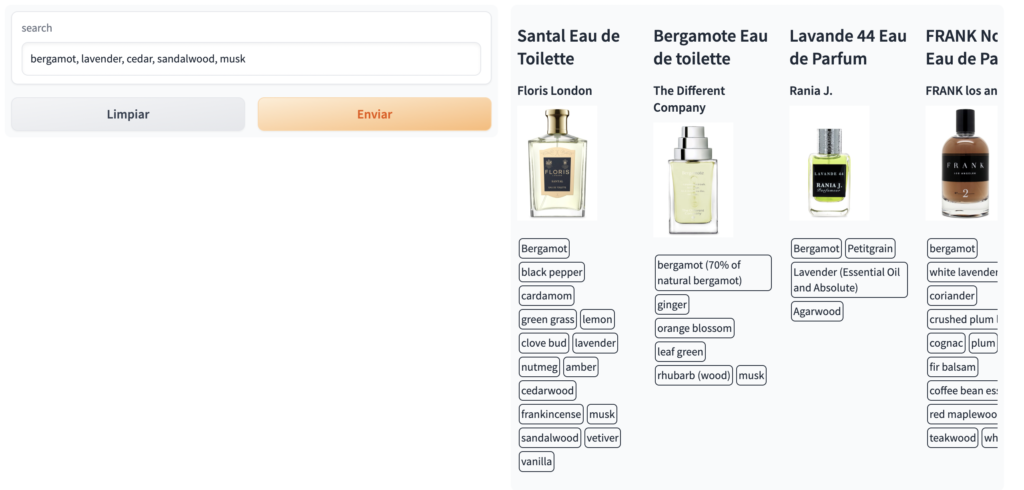
Ahora veamos para el input:
I want a perfume that reminds me of a forestRespuesta: cedarwood, oakmoss, moss, vetiver, pine
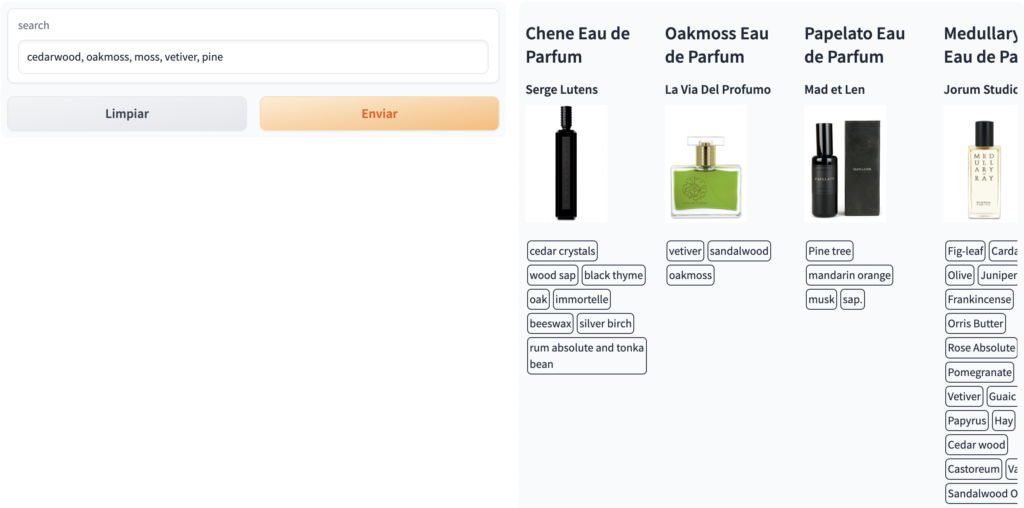
Utilizando las notas recomendadas por el LLM como parámetros de búsqueda, podemos obtener una lista de perfumes que se ajusten a la situación específica descrita.
Conclusión
Hemos creado un buscador simple, potenciado con LLM. Esto demuestra cómo se puede optimizar y personalizar un proyecto fusionando buscador y LLM. No obstante, el desarrollo de proyectos siempre tiene una naturaleza experimental. Es crucial realizar pruebas A/B, para comprobar si estas funcionalidades realmente benefician a los usuarios y siempre actúan como esperamos. Adicionalmente, un buscador sólido normalmente incluye varios elementos que no mencionamos en este post, como:
- Ingesta optimizada de documentos.
- Fallbacks.
- Cold-start de nuevos productos.
- Rankers.
- Almacenamiento en caché.